





| 曙光已现 RISC-V助力国产SoC腾飞 | ||
|
2019年07月22日
|
来源:CEF组委会 |
 
|
在全球处理器领域,以X86架构和ARM架构为主流的指令集架构占据了绝对优势。架构授权成为我国处理器厂商发展无法越过的屏障以及发展保持持续性的潜在不利因素。以RISC-V(第五代精简指令处理器)为代表的开源指令集架构的出现,被业内视为最有可能打破目前处理器生态格局的途径。近年来,RISC-V在世界范围内逐渐步入发展热潮。2018年以来,RISC-V在我国也受到越来越多的重视,中国RISC-V产业联盟和中国开放指令生态系统(RISC-V)联盟相继成立。如何利用RISC-V的开源特性与新兴技术实现国产SoC的国产化发展,成为我国集成电路产业共同关注的话题。
2019年7月11日下午,“基于RISC-V的SoC国产化发展路径”研讨会在成都世纪城新国际会展中心召开。电子科技大学电子科学与工程学院副教授黄乐天、芯来科技创始人& CEO胡振波、知存科技创始人王绍迪从基于RISC-V指令集扩展的专用SoC设计、国产化RISC-V处理器核及配套工具链、RISC-V在AI-SoC芯片中的应用等多方位多角度,阐述了我国利用开源开放的RISC-V构建中国自主可控芯的不断探索。
黄乐天
基于RISC-V扩展指令集的专用SoC设计
电子科技大学副教授黄乐天博士就职于电子科学与工程学院,长期以来从事计算机系统架构与系统级芯片设计交叉方向的研究,包括片上多核处理器与片上网络、异构计算系统与芯片、领域专用处理器与可重构计算等。

传统SoC的设计方向是以软制硬,而目前的SoC必须靠硬件对软件进行加速,这种加速方式主要有下图所示三种。

RISC-V除常规指令之外,还有定制指令,并为其预留了编码格式,利用预留编码格式,设计人员可以为他们想要加速的应用程序添加所需的任何指令。这是一个强大的功能,因为它不会破坏任何软件兼容性,同时为发明和差异化留出空间。黄博士的团队基于RISC-V架构设计了基于自定义扩展指令的神经网络加速器。
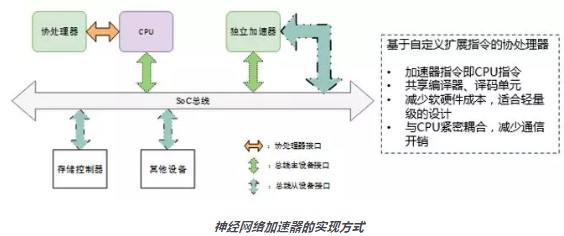
加速器中,5个加速模块共用RoCC接口,需要对输入向信号做一到多仲裁,输出向信号做多到一仲裁。
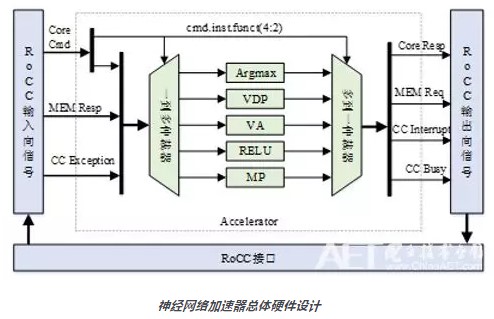
经验证,该加速器的每个模块都能有效地加速相应的计算,且向量长度越长,加速效果越明显。目前国产化的RISC-V处理器大多把其当成ARM的替代品,对于指令扩展和专用SoC设计的支持不足。未来,黄乐天团队在人工智能/神经网络领域,需要继续探索指令扩展加速器与专用SoC设计方法;同时通过对各种形式加速器的研究逐步形成设计方法学,从而更加广泛的指导专用SoC设计;在前两者研究的基础上提出领域专用(Domain Specific)SoC架构、设计自动化工具和流程,形成可以支持“敏捷开发”的设计自动化工具集。
芯来科技
本土RISC-V的先行者和布道者 赋能国内AIoT产业变革
芯来科技成立于2018年,是中国大陆知名的专业RISC-V处理器内核IP和解决方案公司,同时还是中国RISC-V产业联盟(CRVIC)副理事长单位,以及中国开放指令集生态(RISC-V)联盟(CRVA)会员单位,致力于与上下游合作伙伴共同构建RISC-V的产业生态系统。芯来科技创始人& CEO胡振波出版了国内第一本和第二本RISC-V中文书籍,堪称中国本土RISC-V的先行者和布道者。

芯来科技推出的N200系列RISC-V处理器内核IP,专为超低功耗与嵌入式场景而设计,达到业界一流的指标,非常适合替代传统的8051与ARM Cortex-M系列内核。该内核IP系列已经过量产验证,目前已经全面推向市场。
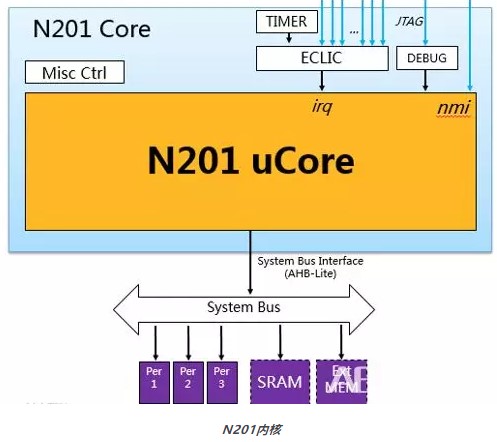
其中,N201内核是一款入门级商用RISC-V处理器内核,可广泛应用于对面积、成本和功耗敏感的IoT领域芯片的微控制部分。N201内核支持RISC-V RV32IC/EC指令集架构、支持机器模式(Machine Mode),可完美替代ARM Cortex-M0或传统8051八位内核。
同时,芯来科技还推出一项RISC-V处理器内核IP普惠计划——“一分钱计划”,用户只需三步便可以加入到芯来“一分钱计划”,就可几乎免费地获取与使用N201内核。

除了标准的处理器内核IP,芯来科技还提供RISC-V专用处理器、软件工具链、SoC子系统的定制服务和解决方案,从而赋能客户实现产品的差异化与高效的性价比。

随着深度学习的进一步发展和AI芯片算力的提升,边缘人工智能芯片将迎来更大的爆发点。安防、自动驾驶、智慧城市、智慧家庭等应用场景都将逐步走向落地。据有关预测,未来2-5年,边缘人工智能芯片市场需求将增长至3000亿人民币。而AI芯片作为AI的载体,被大家寄予厚望,尤其是高算力、低成本、低功耗的AI芯片。

得益于免费、开源、可模组化特色,基于RISC-V打造低功耗AI芯片成为一个新的解决思路。RISC-V在AI中的优势非常明显:(1)性价比高,可显著降低边缘AI芯片的成本;指令集精简,逻辑硬件少,芯片面积小;可按需自由组合的模块化指令集,针对专用芯片降低芯片面积;无向前兼容负担,芯片面积小;(2)高效,精简指令集,硬件简单、功耗低,工作频率高;(3)灵活,可自定义指令,适用于专用场景,从而提高效率;(4)良好的生态发展,目前已经有200多家公司和组织成员参与维护和更新指令集,支持Linux、RTOS、RT-Thread等,且工具链愈加完善,未来随着越来越多玩家的加入,还将涌现越来越好的软件。
目前,RISC-V在AI中的商业化也取得了多项进展,在美国,NVIDIA早早就加入了RISC-V基金会,并做了不少研究,近日还公开了在深度神经网络(DNN)中应用RISC-V指令集的可能。Mythic也与其他十几家企业和组织共同成立了OpenHW组织,特斯拉也加入RISC-V基金会,并考虑在新款芯片中使用免费的RISC-V设计。在国内,比特大陆在Sophon Edge人工智能芯片中就采用了RISC-V架构,嘉楠耘智也在去年年底发布了全球第一款基于RISC-V的边缘计算商用芯片。
在很多AI推理运算中,90%以上的运算资源都消耗在数据搬运的过程。芯片内部到外部的带宽以及片上缓存空间限制了运算的效率。现在工业界和学术界很多人认为存算一体化是未来的趋势。
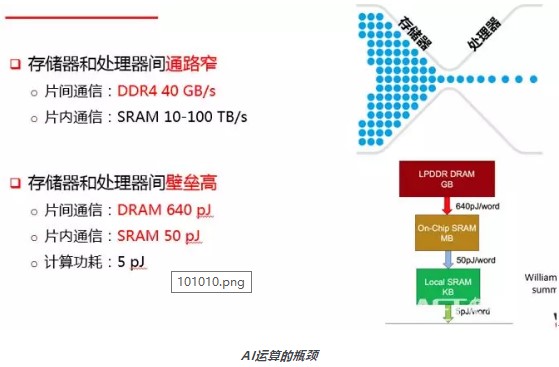
存算一体化分为几种:DRAM和SSD中植入计算芯片或者逻辑计算单元,可以被叫做存内处理或者近数据计算,这种方式非常适合云端的大数据和神经网络训练等应用;另一种就是存储和计算完全结合在一起,使用存储的器件单元直接完成计算,比较适合神经网络推理类应用。

知存科技是后者,即将存储和计算结合到闪存单元中的存算一体。知存科技使用单一浮栅存储阵列完成深度学习网络的存储和计算功能,运算过程中无需缓存、内存和逻辑运算加速器,在存储单元器件中直接完成计算,从而彻底解决人工智能运算中的存储墙和算力问题。
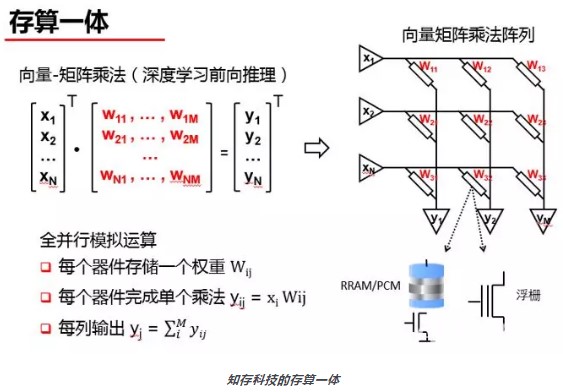
目前知存科技基于自主研发的存算一体架构和存储阵列的嵌入式智能语音芯片已经完成流片,支持DNN、LSTM等多种常用网络,支持可变运算和参数精度,预计2019年年末进入量产。
研讨会现场讨论热烈,演讲嘉宾和与会听众就基于RISC-V的国产SoC的发展展开深入探讨。大家一致认为,国产SoC想要摆脱X86、ARM架构的限制,实现真正的崛起,RISC-V将是一个最大的机遇,它给了我们和全球一致的起跑线,错过RISC-V 我们可能又将错过一个时代!欣慰的是,国内RISC-V生态体系正在逐步建立起来,也涌现了一批代表性企业真正投入到基于RISC-V指令集的处理器内核及相应开发环境等工作中。可以预见,未来几年,RISC-V将助力国产SoC迎来最佳发展期。



